[toc]
DISCUSSION AND CONCLUSION
TWOSOME:
- 通过强化学习将LLMs与环境对齐,来解决决策任务,并且不需要任何准备的数据集或环境的先验知识,同时不会显著损失LLM的原始能力。
- 更可控、更可行、可解释性更强。
- 具有单词归一化,采样效率更高 。
- 泛化能力强。
- 计算量比较大,批处理规模较小。
Introduction
- 大模型在简单决策任务上会失败,原因:
- LLM会产生无效动作。
- LLM无法准确的知道环境的动态变化。
- TWOSOME:通过强化学习将LLMs与环境对齐
- 不让LLM直接生成动作,而是使用LLM提供的每个令牌的对数似然分数来计算每个动作的联合概率,并形成有效的行为策略。
- 最近策略优化(PPO)和环境奖励来优化LLM代理,消除动态转换导致的失调。
- 提出了基于代词数量和作用词数量的代词归一化和单词归一化来纠正较长的行动往往具有较低的联合概率,从而导致行动分布的不合理不平衡。
RelatedWork
Embodied Agents with LLMs
- 过于依赖大模型的故有能力,很难应用到规模较小的模型上。
- 专注于玩具环境中的简单原始动作,没有丰富的语义,导致LLM的功能利用不足,并且未能观察到即时设计的影响,并解决动作空间上的不平衡。
Finetuning LLMs
- 使用监督学习,通过在环境中随机采样来微调具有预先收集的具体经验的LLM,而不是从头开始执行决策任务。
Preliminaries
LLMs:使用无监督学习从文本数据中学习。
- 将可变长度符号序列的联合概率优化为条件概率的乘积。
- $$P (x) = \prod^n {i=1} P (s_i|s_1, …, s{i−1})$$
LoRA:将可训练秩分解矩阵合并到LLM的每个层中的参数和计算高效微调方法。
RL:将决策问题表示为马尔可夫决策过程(MDP)。MDP由元组(S,A,T,R,γ)定义,其中S是状态空间,A是动作空间,T是状态转移概率,R是奖励函数,γ是折扣因子。智能体据观察结果选择行动,旨在最大化预期折扣累积奖励。
PPO:近端策略优化。通过限制策略更新幅度,使得每一步训练都不会偏离当前策略太多,同时高效利用采样数据。
Aligning LLMs with Embodied Environments:具体化环境中将LLM部署为交互式代理,其中LLM接收文本观察并生成在环境中执行的文本操作。
TWOSOME
Valid Policy Generation
- 行动提示(Action Prompt):将每个行动与唯一语义提示关联,LLMs生成行动的概率,而非直接生成行动。
- 策略形成:通过LLMs的词元概率计算行动的联合概率,并归一化为有效行为策略。
公式(1):计算行动的联合概率
.png)
解释:
- $a_k$ 是一个行动,由一系列词元(tokens)组成,即$a_k$ =$${w_1^k,w_2^k,…,w_{N_k}^k}$$。
- s 是当前的观察状态。
- $$P_{token}(a_k∣s)$$ 是行动 $a_k$ 在状态 s 下的联合概率。
- $$P(w_i^k∣s,w_1^k,…,w_{i−1}^k)$$ 是在状态 s 和已生成词元 $$w_1^k,…,w_{i−1}^k$$ 的条件下,生成词元 $$w_i^k$$ 的概率。
- 假设行动 $$a_k$$ 是 “pick up the tomato”,由词元 {pick, up, the, tomato} 组成,那么联合概率为:
公式(2):归一化行动概率
.png)
解释:
- $$P(a_k∣s)$$ 是行动 $$a_k$$ 在状态 s 下的归一化概率。
- $$exp(log P_{token}(a_k∣s))$$ 是联合概率$$P_{token}(a_k∣s))$$的指数形式。
- 分母是所有可能行动的指数形式联合概率之和,用于归一化。
示例: 假设在状态 s 下,有两个行动 $$a_1$$ 和 $$a_2$$,它们的联合概率分别为 $$P_{token}(a_1∣s)=0.05$$ 和 $$P_{token}(a_2∣s)=0.15$$,那么归一化后的概率为:
$$P(a_1∣s)=\frac{exp(log0.05)}{exp(log0.05)+exp(log0.15)}=\frac{0.05}{0.05+0.15}=0.25$$
$$P(a_2∣s)=\frac{exp(log0.15)}{exp(log0.05)+exp(log0.15)}=\frac{0.15}{0.05+0.15}=0.75$$
通过归一化,确保了所有行动的概率之和为1,便于策略的选择和比较。
ACTION PROMPT NORMALIZATION
公式(1)存在问题:行动提示(action prompts)的长度差异会导致联合概率(joint probabilities)计算中的不平衡问题。具体来说,较长的行动提示倾向于具有较低的联合概率,即使它们在实际环境中是更合理的行动。这种不平衡会影响策略的稳定性和训练效率
解决:
Token Normalization(词元归一化)
- 通过将每个行动提示的联合概率除以该行动提示的词元数(tokens)来调整概率分布。具体公式如下:.png)
- $$P_{tn}(a_k∣s)$$ 是归一化后的概率。
- $$P_{token}(a_k∣s)$$ 是原始的联合概率。
- $$N_k$$ 是行动提示 $$a_k$$ 的词元数。
- 通过词元归一化,较长的行动提示的联合概率会被调整到与较短的行动提示相同的量级,从而避免因为词元数量不同而导致的不平衡。
- 通过将每个行动提示的联合概率除以该行动提示的词元数(tokens)来调整概率分布。具体公式如下:.png)
Word Normalization(词归一化)
词归一化通过将每个行动提示的联合概率除以该行动提示的词数(words)来调整概率分布。.png)
$$P_{tn}(a_k∣s)$$ 是归一化后的概率。
$$P_{token}(a_k∣s)$$ 是原始的联合概率。
$$W_k$$ 是行动提示 $$a_k$$ 的词数。
与词元归一化类似,词归一化也通过调整概率分布来避免因为词数不同而导致的不平衡。词归一化更适合处理那些由多个词组成的行动提示,因为它考虑了词的实际数量而不是词元数量。
Comparing the Two Normalizations:
对比维度 词元归一化(Token Normalization) 词归一化(Word Normalization) 定义 基于词元数量的归一化 基于词数量的归一化 优点 简单直接,有效调整 更符合语言习惯,更好平衡 缺点 过度归一化,对词元数量敏感 计算稍复杂,对词数敏感 实验表现 在某些任务中表现较好,但收敛速度可能较慢 在大多数任务中表现更好,收敛更快
Parameter-Efficient PPO Finetuning
Architecture
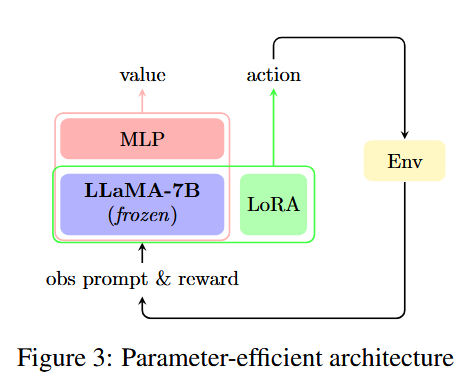
- 冻结的LLaMA-7B模型:
- LLaMA-7B模型是整个架构的基础,其参数在训练过程中保持冻结,不进行更新。
- 这部分模型负责生成文本表示,为后续的策略优化提供基础。
- 额外的MLP层:
- 在冻结的LLaMA-7B模型的最后一个Transformer块之后,添加了一个额外的多层感知器(MLP)网络,用作批评家(critic)。
- 批评家的MLP网络的输入是观察提示的最后一个词元,输出是对当前观察提示的估值(value)。
- LoRA适配器:
- 在冻结的LLaMA-7B模型中,添加了低秩适配器(LoRA)进行参数化微调。
- LoRA通过引入低秩矩阵来近似参数更新,从而减少需要优化的参数数量,提高训练效率。
- 动作和价值输出:
- 动作输出:冻结的LLaMA-7B模型与LoRA适配器结合,生成动作概率。
- 价值输出:额外的MLP网络生成当前状态的价值估计。
Training
环境交互
- 观察提示:环境提供观察提示(obs prompt)和奖励(reward)信号。
- 动作输出:冻结的LLaMA-7B模型与LoRA适配器结合,生成动作概率。
策略优化
- PPO算法:基于累积奖励(advantage)进行优化。
- 优势函数:A(st,at)=Q(st,at)−V(st),其中Q(st,at)是动作值函数,V(st)是价值函数。
- 目标函数:PPO目标函数确保策略更新的一致性和稳定性。
价值网络优化
- 损失函数:最小化价值函数的均方误差(MSE)。
- 优化器:使用Adam优化器。
Prompt Design
四个原则
- 提示的连贯性:
- 定义:观察提示和行动提示应具有连贯性,便于LLMs理解和生成合理的行动。
- 具体做法:观察提示以“you should”结尾,行动提示以“next step is to”开头,确保提示之间的逻辑连贯性。
- 示例:
- 观察提示:You see a tomato, a bowl and a cutting board. To make a tomato salad, you should
- 行动提示:pick up the tomato, take the bowl, move to the cutting board, chop the tomato, serve the dish
- 冠词的敏感性:
- 定义:LLMs对冠词(如“the”、“a”、“an”)非常敏感,提示中应包含适当的冠词以提高LLMs的识别率。
- 具体做法:在行动提示中明确包含冠词,如“pick up the tomato”而不是“pick up tomato”。
- 示例:
- 正确提示:pick up the tomato
- 错误提示:pick up tomato
- 重复词强化概率:
- 定义:通过在观察提示中重复关键名词,可以提高这些词在LLMs生成中的概率。
- 具体做法:在观察提示中多次提及任务相关的关键名词,如“tomato”、“lettuce”等。
- 示例:
- 观察提示:You see a tomato on the table. Your task is to make a salad consisting of tomato.
- 行动语境适配:
- 定义:根据环境状态设计行动提示,确保行动的合理性和环境适配性。
- 具体做法:根据当前环境状态和任务目标,设计与环境状态相匹配的行动提示。
- 示例:
- 当前状态:Agent is in the kitchen, holding a tomato.
- 行动提示:move to the cutting board, chop the tomato
Experiments
Setup
环境:
- Overcooked:这是一个经典的决策环境,任务是制作番茄沙拉和番茄生菜沙拉。
- VirtualHome:这是一个模拟的家庭环境,任务包括加热煎饼和娱乐(准备零食、看电视)。
方法:
- PPO:传统的强化学习方法。
- TWOSOME without finetuning:类似于 SayCan 的方法,不进行微调。
- TWOSOME without normalization:不使用归一化。
- TWOSOME with token normalization:使用词元归一化。
- TWOSOME with word normalization:使用词归一化。
超参数
- 网络架构:冻结的 LLaMA-7B 模型,添加 LoRA 适配器和 MLP 批评家网络。
- 训练设置:使用半精度浮点数(float16),训练和测试在单个 NVIDIA Tesla A100 和 NVIDIA RTX A6000 GPU 上完成。
The impact of different Normalizations in TWOSOME
图5a
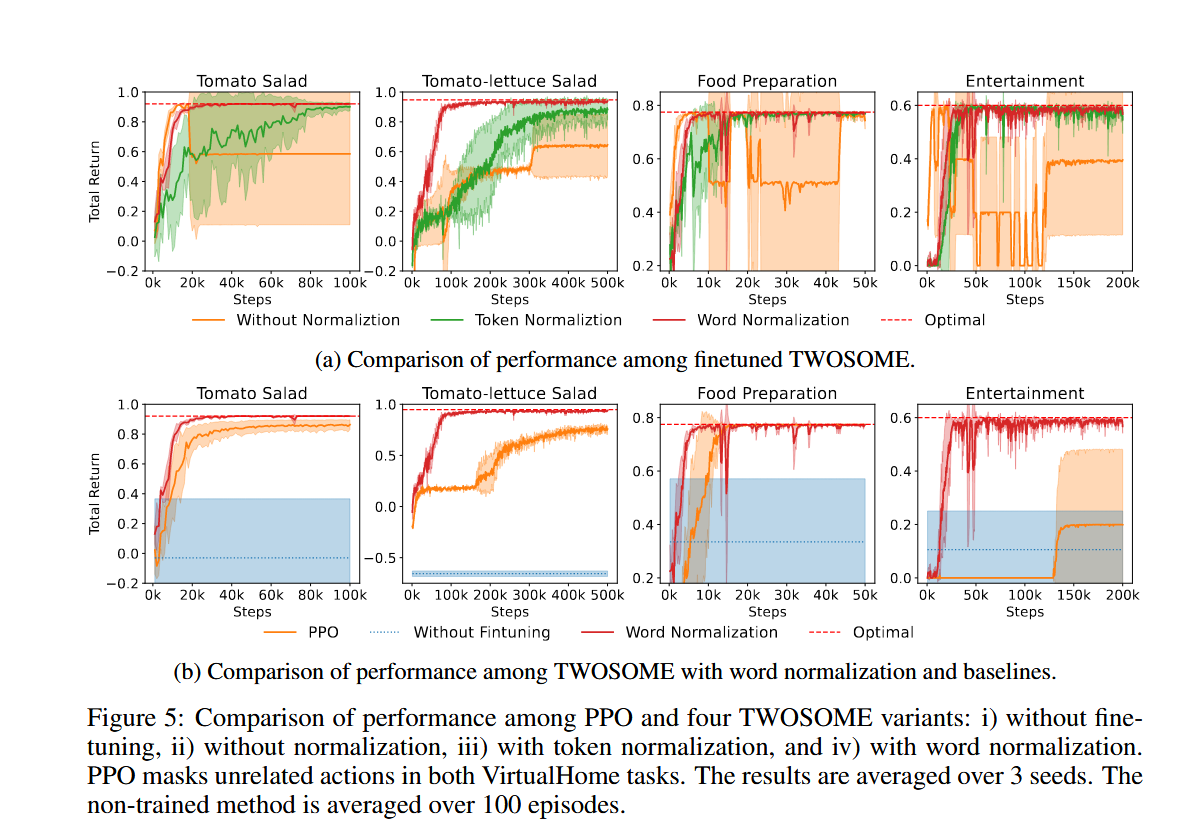
- TWOSOME with word normalization:在所有任务中表现出最佳性能,成功率达到 100%。
- TWOSOME without normalization:在某些任务中表现不稳定,尤其是在行动提示长度差异较大的情况下。
- TWOSOME with token normalization:虽然提高了稳定性,但在收敛速度上不如词归一化。
TWOSOME vs Baselines
图5b
与 SayCan(baseline) 的对比
- Overcooked 环境:
- 番茄沙拉任务:TWOSOME without finetuning 的成功率为 0.36 ± 0.04,而 TWOSOME with word normalization 的成功率为 1 ± 0。
- 番茄生菜沙拉任务:TWOSOME without finetuning 的成功率为 0 ± 0,而 TWOSOME with word normalization 的成功率为 1 ± 0。
- VirtualHome 环境:
- 加热煎饼任务:TWOSOME without finetuning 的成功率为 0.81 ± 0.01,而 TWOSOME with word normalization 的成功率为 1 ± 0。
- 娱乐任务:TWOSOME without finetuning 的成功率为 0.45 ± 0.05,而 TWOSOME with word normalization 的成功率为 1 ± 0。
与PPO相比
- Overcooked 环境:
- 番茄沙拉任务:PPO 需要 5e5 步才能收敛,而 TWOSOME with word normalization 在更少的步数内达到更高的成功率。
- 番茄生菜沙拉任务:PPO 需要 5e5 步才能收敛,而 TWOSOME with word normalization 在更少的步数内达到更高的成功率。
- VirtualHome 环境:
- 加热煎饼任务:PPO 需要 5e4 步才能收敛,而 TWOSOME with word normalization 在更少的步数内达到更高的成功率。
- 娱乐任务:PPO 需要 2e5 步才能收敛,而 TWOSOME with word normalization 在更少的步数内达到更高的成功率。
Open-vocabulary Task Generalzation
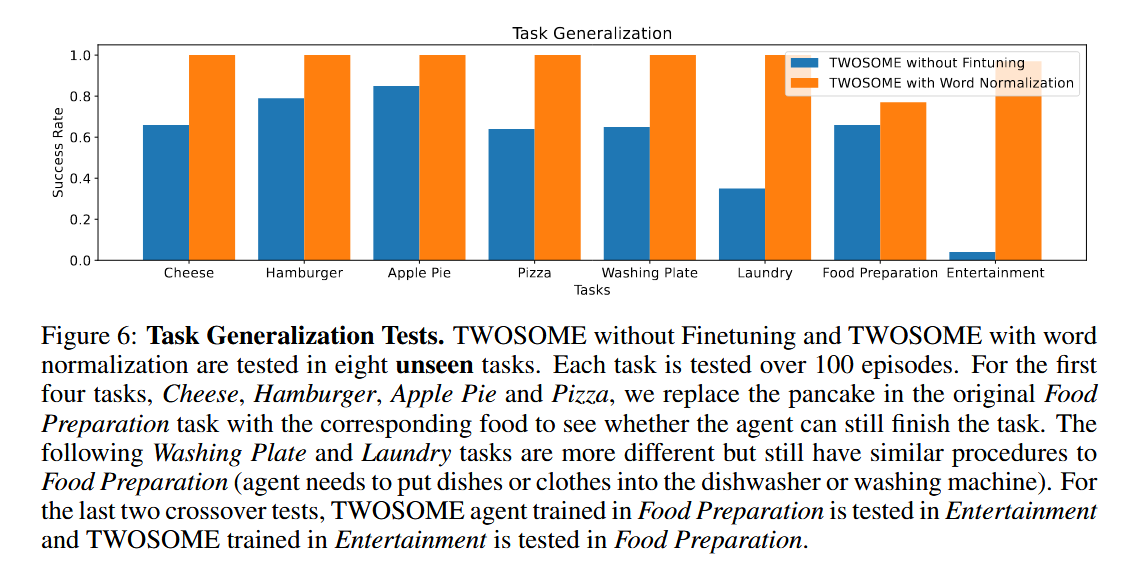
我们在八个新的未见过的任务中评估了 TWOSOME 的泛化能力,这些任务包括:
- Cheese、Hamburger、Apple Pie、Pizza:替换原始任务中的食物。
- Washing Plate、Laundry:更复杂的任务,需要多步操作。
- Food Preparation 和 Entertainment 的交叉测试。
实验结果
- TWOSOME with word normalization:在所有八个任务中都表现出色,成功率达到 100%。
- SayCan:在某些任务中表现较差,尤其是在需要复杂操作的任务中。
Impact of Online Finetuning
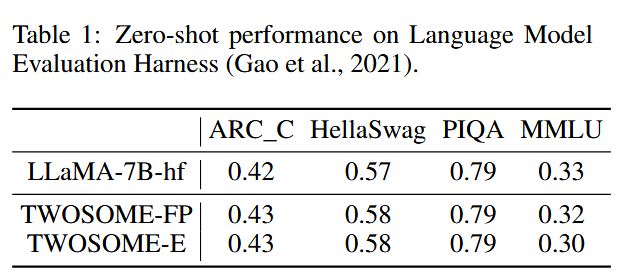
我们在 VirtualHome 任务中评估了在线 PPO 微调对 LLMs 能力的影响
- 评估基准:使用广泛使用的 NLP 基准(Gao et al., 2021)。
- 模型:评估了 TWOSOME with word normalization 在 Food Preparation 和 Entertainment 任务中的表现。
结果
- 零样本性能:TWOSOME with word normalization 在 ARC_C、HellaSwag 和 PIQA 任务中的零样本性能与原始 LLaMA 模型相当,甚至在某些任务中略有提升。
- MMLU 任务:在大多数子任务中,TWOSOME with word normalization 的性能与原始 LLaMA 模型相当,某些子任务中略有下降。
结论
- TWOSOME with word normalization 在所有任务中表现出最佳性能,成功率达到 100%。
- TWOSOME 框架显著提高了样本效率和性能,优于传统的 RL 方法和提示微调方法。
- TWOSOME 具有良好的泛化能力,能够将学到的技能迁移到未见过的任务。
局限性
- 计算成本:TWOSOME 需要为每次行动采样向 LLMs 提供所有有效行动,导致计算量和时间成本增加。
- 训练稳定性:在某些情况下,训练过程可能会出现不稳定,需要 careful 的超参数调整。
创新点
- 高效策略生成:TWOSOME通过查询LLMs的分数来确定行动的概率,而不是直接生成行动,确保了策略的有效性和环境适配性。这种方法不仅避免了LLMs生成无效行动的问题,还充分利用了LLMs的语言理解和生成能力。
- 行动提示归一化:为了解决行动提示长度差异导致的概率不平衡问题,TWOSOME提出了词元归一化和词归一化技术。这些技术通过调整概率分布,避免了因为词元或词数不同而导致的不平衡,显著提高了训练的稳定性和收敛速度。
- 参数化PPO微调:TWOSOME通过冻结LLaMA-7B模型并使用低秩适配器(LoRA)进行参数化微调,减少了需要优化的参数数量,提高了训练效率。同时,通过添加额外的MLP层作为批评家网络,结合PPO算法进行策略优化,确保了训练的稳定性和快速收敛。
- 提示设计原则:文章总结了四个提示设计原则,包括提示的连贯性、冠词的敏感性、重复词强化概率和行动语境适配。这些原则通过精心设计的提示,显著提高了LLMs的决策能力和泛化能力。
优化策略
计算效率
针对TWOSOME框架的计算效率优化,可以从以下几个方面进行改进:
1. 高效采样策略
问题分析:TWOSOME需要为每次行动采样向LLMs提供所有有效行动,导致计算量和时间成本增加。
改进方法:
- 基于优先级的采样:根据行动的历史成功率或相关性,为行动分配优先级。在每次采样时,优先选择高优先级的行动进行评估,减少低优先级行动的采样频率。
- 分层采样:将行动按照类型或功能进行分组,形成层次结构。在采样时,先从高层类别中选择,再逐步细化到具体行动,减少每次采样需要评估的行动数量。
- 行动过滤:在采样前,通过简单的规则或启发式方法过滤掉明显不合理的行动,减少需要评估的行动范围。
2. 模型压缩
问题分析:大型语言模型(LLMs)的参数量巨大,导致计算和存储成本高。
改进方法:
- 剪枝:去除模型中不重要的连接或神经元,减少参数数量。可以通过分析权重的重要性,删除那些对模型输出影响较小的连接。
- 量化:将模型的权重从高精度表示转换为低精度表示(如从32位浮点数转换为8位整数),减少存储需求和计算复杂度。
- 知识蒸馏:训练一个较小的学生模型来模仿大型教师模型的行为,通过保留主要功能的同时减少参数量。
3. 硬件加速
问题分析:计算资源的限制影响了训练和推理的速度。
改进方法:
- GPU优化:利用GPU的并行计算能力,优化模型的计算过程。可以通过使用CUDA等并行计算框架,加速矩阵运算和神经网络的前向、反向传播。
- 分布式计算:将计算任务分布在多个GPU或计算节点上,实现并行训练和推理。可以通过数据并行或模型并行的方式,提高计算效率。
- 专用硬件:利用专用的AI加速硬件,如TPU,进一步提升计算速度和能效。
4. 优化算法改进
问题分析:现有的优化算法可能不是最高效的,导致训练过程缓慢。
改进方法:
- 自适应优化算法:使用更先进的自适应优化算法,如AdamW、RAdam等,这些算法能够自动调整学习率,提高收敛速度和稳定性。
- 混合精度训练:结合不同精度的数值表示进行训练,如在前向传播中使用较低精度,反向传播中使用较高精度,减少计算资源的消耗同时保持模型的准确性。
- 异步更新:采用异步更新机制,允许多个计算单元同时进行计算并异步更新模型参数,提高资源利用率和训练速度。
5. 动态计算资源分配
问题分析:在不同的训练阶段或任务中,计算资源的需求可能不同。
改进方法:
- 资源调度算法:开发智能的资源调度算法,根据任务的复杂度和当前的训练进度,动态分配计算资源。在任务初期或复杂任务中分配更多资源,在任务后期或简单任务中减少资源分配。
- 弹性扩展:利用云计算等资源弹性扩展的特性,在需要时自动增加计算资源,在任务完成后释放资源,降低成本。
- 优先级调整:根据任务的重要性和紧急程度,动态调整任务的优先级,合理分配计算资源,确保关键任务得到足够的资源支持。
通过这些改进方法,可以有效提高TWOSOME框架的计算效率,减少计算资源的消耗,同时保持模型的性能和效果。这将使TWOSOME在实际应用中更具可行性和竞争力。
其他优化
训练稳定性提升
- 问题:在某些情况下,训练过程可能会出现不稳定,需要谨慎的超参数调整。
- 改进方向:
- 自适应学习率:引入自适应学习率调整机制,根据训练过程中的反馈动态调整学习率,提高训练稳定性。
- 正则化技术:增加更多的正则化技术,如dropout、权重衰减等,防止过拟合,提高模型的泛化能力。
- 多任务学习:引入多任务学习框架,通过同时优化多个相关任务,提高模型的稳定性和鲁棒性。
3. 提示设计自动化
- 问题:当前的提示设计依赖于人工总结的原则,可能不够灵活和全面。
- 改进方向:
- 自动提示生成:开发自动化的提示生成工具,能够根据任务和环境自动生成优化的提示。
- 强化学习优化提示:使用强化学习方法优化提示设计,通过环境反馈自动调整提示内容。
- 提示效果评估:建立提示效果的量化评估指标,能够自动评估和筛选出最优的提示设计。
If you like this blog or find it useful for you, you are welcome to comment on it. You are also welcome to share this blog, so that more people can participate in it. If the images used in the blog infringe your copyright, please contact the author to delete them. Thank you !